Heuristics to detect malware distributed via Web
Two years ago I started a project, for fun, to try to catch as much malware and URLs related to malware as possible. I have written about this before. In this post I’ll explain the heuristics I use for trying to classify URLs as malicious with “Malware Intelligence” (the name of the system that generates the daily Malware URLs feed). What a normal user sees in any of the 2 text files offered are simply domains or URLs that I classified as “malicious”. But, how does “Malware Intelligence” classifies them as malicious? What heuristics, techniques, etc… does it use?
Malware Intelligence
The server processes in Malware Intelligence take URLs from many sources for later analysis. Some sources are public and others are not. Each URL is put in a queue and, from time to time, a process called “URLAna” performs some checks to determine if the URL seems to be malicious or not. The tool URLAna will call smaller tools that will return a score: a score bigger than 0 means that something was found. A score of 0, nothing bad was found. If after running each mini-tool against the URL or domain its score is bigger than 4, then, the URL is considered “malicious”. I do not use negative scores at all because I consider them a bad idea (for this project).
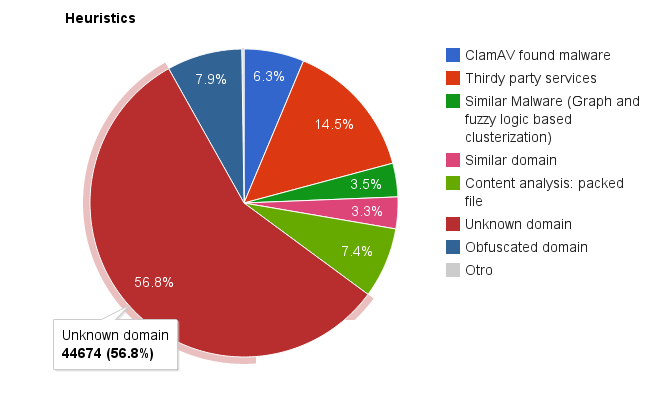
Both hourly and daily, statistics are gathered about the number of URLs detected, when, how, etc… These statistics and many more features can be seen in the (private) Malware Intelligence’s web page. Let’s see one graphic from the statistics web page about the number of URLs classified as malicious by each heuristic before actually explaining them:
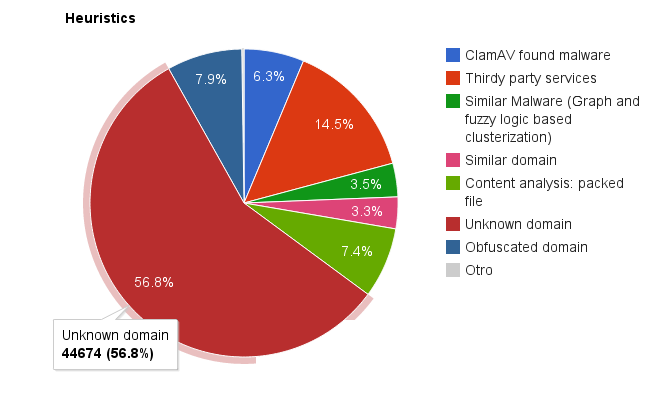
Statistics for each heuristic used by the Malware Intelligence’s process URLAna.
Unknown domain
As we can see in the picture, the heuristic that catches more bad URLs is “Unknown domain”: typically ~60% of URLs. This heuristic simply does the following:
- Download the Alexa’s Top 1 Million domains and save them to a database.
- Add (but do not delete) new domains daily.
- Possible false positives and manually excluded domains goes also to this table.
- When URLAna calls this process I simply check if the domain is in this daily updated table. If it isn’t, I consider it “suspicious” and give back a score of 1.
This heuristic doesn’t say that anything is bad. It simply says that “this is unknown and could be bad”. However, in my experience, blocking domains outside the Alexa’s Top 1 Million blocks more than 60% of distributed malware.
And, well, this is how I can “detect” more than half of the malicious URLs Malware Intelligence processes daily. Let’s continue with the next high scoring heuristic: “Thirdy Party Services”.
Thirdy party services
This heuristic uses 3rd party services, as it’s clear from its name. Namely, the following:
- Surbl: Extracted from their web: “SURBLs are lists of web sites that have appeared in unsolicited messages“. This service offers an API I use to check if the domain is “bad”. If Surbl reports “something” about the URL, a score of 1 is added to the URLs.
- SpamHaus: This is a well known service for downloading long lists of known spammers but, also, they add to the lists malware domains. As with Surbl, it exports an API that I use to check if the domain is considered “bad”. If so, it scores +1.
- Google Safe Browsing: This is a Google project that let’s you check if one URL or domain is/was considered bad by their own automated malware analysis systems. As with the previous cases, they export an API that I make use of. However, GSB is more focused on malware than in spam and, as so, I add, directly, a score of 4 points if GSB says that something was found for that URL.
And that’s all about this easy to implement mini tool. This heuristic is the 2nd one detecting malicious URLs. However, compare the percentages: the “unknown domain” rule detects ~60% of malicious URLs, this one ~15%. Notice the difference? Each time you add a new heuristic to detect more malicious URLs you will discover that the amount of work required for adding only a few ones is huge (and I’m ignoring the fact that there is actually a lot of work behind all these 3 services) Don’t believe me? Let’s continue seeing more heuristics, some rather easy and others not that easy and comparing the results…
Obfuscated domain (or URL)
The 3rd one at the podium is this rule. It’s as simply as the following: if the URL or the domain are obfuscated, then its score is increased by 1. Simple, isn’t it? Yes, as soon as you have defined “what is obfuscated” and coded it. In my case, I simply make use of 2 not so complex rules:
- If there are more than 6 continuous vowels or consonants, I consider it obfuscated. In either the domain, sub-domain or in the URI.
- For domains longer than 8 characters if the set with the minimum of either vowels or consonants multiplied by 3 and adding 2 is lower than the total of the other set, I consider it malicious.
Complicated? Not so complex when you have 40 million known bad URLs to test with. Hard at first: this is one of the first heuristics I added and one of the more I modified. At first. Why? Let’s take a look to one good URL from Google:
https://chrome.google.com/webstore/detail/web-developer/bfbameneiokkgbdmiekhjnmfkcnldhhm
This (damn) URL is the link for the Web Developer extension for Chrome. One question: do you consider this URL obfuscated or not? I would say yes. Is malicious? No.
Content analysis: packed file
The 4th heuristic(s) at the top is this one. This heuristic, only applied for PE and ELF files analyses with Pyew the program (by the way, a URL pointing directly to a program automatically scores +1) and determines if it’s:
- Packed.
- Packed and obfuscated.
Pyew already have one of these heuristic implemented (the obfuscation related one). The other heuristic use is implemented (only for PE files) by the Python library pefile, by Ero Carrera. There is no magic here: a somewhat “big” binary with very little functions or with code that when analysing produces too many errors and, still, have one, a few or even no detected function at all is considered probably bad. If the application is “packed”, its score is increased by 1. If it’s obfuscated, by 2. However, this heuristic, the one that tries to detect obfuscation (and anti-emulations, etc…), catches like ~50 files per day. Only. Do you want to enhance it to also detect anti-disassembling, for example? Perhaps you get 51 files per day. It can be that my heuristic is bad but I would not recommend spending too much time on it.
ClamAV found malware
As simply as it sounds: ClamAV found malware in the contents of that URL. That’s all, it simply adds 3 points to the total score in case something was found. I use the Python bindings for ClamAV called pyclamd. I can use one more AV engines/products. Or perhaps a lot of them. Or perhaps another 3rd party “free” service like OpSwat Metascan (or VirusTotal, which is better) but… how many URLs are detected this way? A big number of them but not so many. Do you want to add also false positives from more than one AV vendor? I don’t. But this is only my opinion.
Similar malware
This heuristic uses a set of algorithms to cluster unknown malware executables (PE & ELF). It uses Pyew and the algorithms implemented in the Pyew’s tool gcluster. If the file (contents) under analysis is an executable file and via these graph based malware clusterization algorithms it looks too similar (or equal) to a previously known malware I add 3 points to the score of the URL.
While this heuristic is working, take a look to the percentage of new malware URLs discovered: 3.5% of the total. A lot of work for just the 3.5%. May be it’s a problem of my algorithms, I don’t know. But… I don’t think.
Similar domain
A rather simplistic, even when it seems not, heuristic: if the domain looks too similar to one domain in the first 100.000 records of the Alexa’s Top 1 Million the score is increased by 1. Why? What about a domain named yutuve? What about guugle? Likely being used in a phising campaign or distributing malware.
At first the heuristic used a pure Python implementation of the soundex algorithm. After a while I switched to the SOUNDEX function in MySQL. Results of this heuristic: 3.3%. At least it wasn’t that hard to implement…
All the other heuristics
There are other 2 heuristics I implemented, I still use but I do no maintain and I have no interest in maintaining them at all:
- Suspicious JavaScript. Basically, a pattern matching technique finding for “eval”, “document.write”, “setInterval”, “unescape”, etc… If the patterns are discovered the score is increased by 1. I decided not to loose time adding more “advanced” malicious JavaScript heuristics. The reason? Because it would require a lot of work that must be updated daily. Too much work for a “just for fun” project.
- Known bad URL parameter. Pattern matching, again. During some time I had a system to group and extract some of the most common special URL parameter and file names and then use them as another evidence. I do not maintain this list any more for the same reasons as the previous heuristic. If you want to see some examples: the rules “/bot.exe” or “/.*(update|install).*flash.*player.*.exe” were the ones finding more samples.
Conclusions and possible future work
Detecting malicious content is not easy and requires a lot of work. Detecting more than 50% of the (dumb) malicious URLs and samples is easy. Detecting something bigger than 70% is a big work. Detecting something similar to 75% requires, in my very subjective opinion, more effort than what you spent for detecting all the previous 70% of samples. If you ever blamed $AV for not detecting this or that relatively new malware sample, please think about all the work that must be done to catch that new family.
As for possible future improvements of Malware Intelligence, if at all, I’m thinking about integrating one more tool of mine: MultiAV. It’s a simple interface to various AV products using the command line scanners to get the detection over a file, directory, etc… Also, I have other heuristics on mind, but no one of them is easy and this is a project that I do during my spare time when I feel like spending some hours on it.
The source code for URLAna, as an independent tool, will be published (once I clean it up and all the code specific to my system is removed) in the next months (when I have time). In any case, with all the details given in this blog post one can implement it (surely better than my prototype-that-grown-a-lot) easily.
I hope you liked this post and that you find it useful. Perhaps it may even help you improving your analysis systems or you can borrow some ideas for another project 😉 Also, if you have any idea to improve that system I would be very happy to read/heard about it 🙂
Cheers!